
This research line explores the use of Learning Techniques to different domains, from data center optimization to cancer genomics, leveraging different techniques from statistical Machine Learning to state of the art Deep Learning and Neural Networks, and different programming frameworks.
Summary
Complex systems like data centers and distributed computing infrastructures become a challenge when optimizing and making management decisions. Knowledge about the insights of such systems are crucial for a proper management, but obtaining manually this knowledge by human observation and analysis is hard and not always possible. Data mining, Machine learning and Knowledge Discovery fields, nowadays referred as Data Science, cover the needs for obtaining knowledge from data. By applying those methods, management mechanisms and decision makers can be feed with implicit and latent information, hidden to the human eye, maintain updated their knowledge database, and progressively improve the management policies from infrastructure to software configuration level.
One of the main concerns of our research line is to extract knowledge from distributed systems and data centers, oriented to model the environment holistically and specifically. Such models can be used to workload placement optimization, dynamic infrastructure configuration, detection and prevention of failures and anomalies, and recommendation of actions and policy enforcement among others. For those goals we use methods from classic and statistical Machine Learning to state of the art Deep Learning and Neural Networks, and data processing technologies like Hadoop or Spark, plus Theano, Lassagne, et al.
Objectives
Develop applied learning methods across differnet research areas, including:
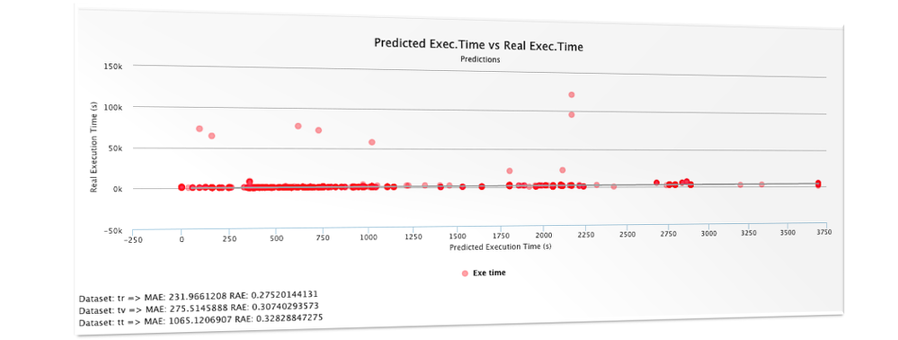
- In the context of the ALOJA project, explore Big Data runtimes performance under different deployment scenarios, by providing data and model-driven prediction, anomaly detection and recommendation on Big Data runtimes benchmarking and performance.
- In the context of the Hi-EST Project, conduct research in Adaptive Learning Algorithms, Task Placement and Scheduling Algorithms, Data Placement Strategies and Software Defined Environments focusing on self-management of hybrid and heterogeneous data centers and workloads.
- In the context of the Cancer research, research on discovering patterns from genomic information towards identifying patients, causes and consequences of tumorous sequences.
